
The Hybrid-POWER Suffix-Tree Walker
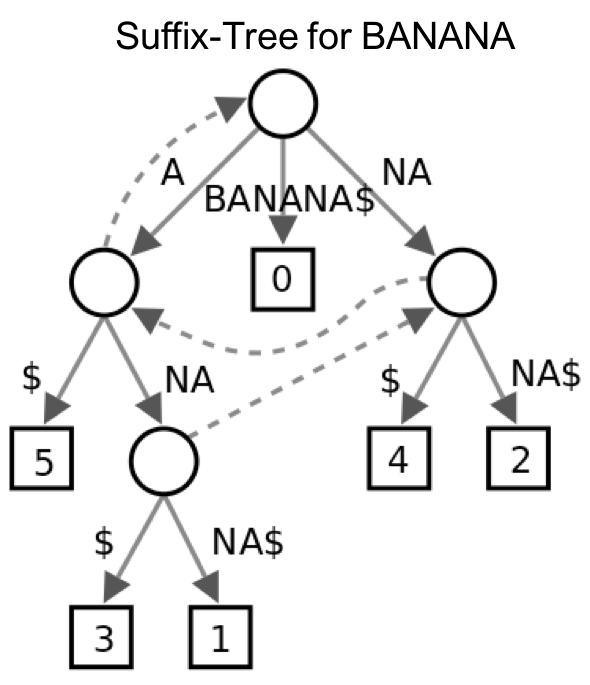


A Suffix tree is a tree data structure that contains all suffixes of a text string in a representation that allows efficient search for substrings, regular expressions or longest common substrings. Suffix trees are often used in compression algorithms and in bioinformatics applications, where they represent DNA sequences. In bioinformatics scenarios with large reference sequences, the efficient implementation of suffix trees is a particular challenge because they have a large memory footprint and rely on low-latency memory operations in a data-dependent random access pattern.
We have an exciting new hardware platform to tackle these challenges. A 10-core IBM POWER8 processor with 80 hardware threads is equipped with 128GB of fast main memory with integrated L4 cache. An FPGA accelerator board is attached with the novel CAPI protocol, which for the first time allows easy and efficient cache-coherent integration of the accelerator into the same memory space. In this thesis, you can contribute to use this compute power and memory infrastructure efficiently for suffix trees.
Tasks
- Concept for CPU/FPGA interplay during tree search and/or build-up
- Implementation for CPU and FPGA, possibly with high-level synthesis
- Continuous modeling and monitoring of performance metrics
Recommended Skills
- Solid programming background (C/C++)
- Any background on heterogeneous or reconfigurable architectures
- Experienced Linux user