
On-the-fly Binary Program Acceleration for Embedded Systems

In a nutshell
Optimize a runtime and just-in-time compilation system for embedded systems (ES)
- Optimize runtime decisions on the embedded system "Odroid" for performance, energy, utilization, and other system requirements
- Update the OpenCL code generation backend to generate ES-specific optimized OpenCL code for the BIG.little architecture and the in-build Mali GPU
- Evaluate the system using a well-known benchmark suite
Modern computer systems supply multiple diverse computing cores. Together with accelerators (GPUs, FPGAs, many-cores, etc.) they form new heterogeneous system architectures and offer a huge potential for optimizing applications. On the other hand, existent software needs adaptation to benefit from the possible performance increase the accelerators provide.
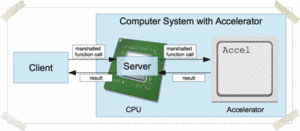
We have developed a Runtime and Just-in-time Compilation System (RTCS, see Figure) that is able to tackle this problem for high-performance computer systems (HPC). The RTCS uses the LLVM compiler infrastructure and is capable of detecting application computationally intensive loops (hotspots). It consists of a framework that supports transparent, just-in-time code generation of accelerated code integrating it into the application at runtime.
The embedded systems domain has a different set of challenges as compared to HPC (e.g. energy vs performance goals). In the next steps, we want to examine the performance of the RTCS for the embedded system domain. In this instance, we want to focus on the ODROID board (Odroid-XU3), which is a low-power ARM-based system featuring heterogeneous CPU cores and an onboard GPU. In this work, you would have to
- explore code generation (from LLVM to OpenCL) for the Mali GPU and optimize it for a selected set of benchmark applications
- determine the optimal resource (big CPU, LITTLE CPU, Mali GPU) to offload the hotspot to based on current system goals
We provide
- Interesting, research related topics
- Heterogeneous server with multiple state-of-the-art soft-/hardware
- Good work atmosphere
- Optionally: work area in student lab
Requirements
- Good programming skills (C/C++), basic knowledge in OpenCL
- Motivated, able to work autonomously
- Interest in embedded systems
- Basic knowledge in compilers (preferably LLVM)